Eine Einführung in die Grundlagen von KI und Machine Learning
Text: Simon Hestermann, Bilder: Simon Hestermann, Midjourney Bot
Die technische Entwicklung Künstlicher Intelligenz (KI) hat in kurzer Zeit rasant an Fahrt aufgenommen. Der schnelle Fortschritt wirft viele Fragen auf: Wie können wir die Technologie gewinnbringend nutzen? Wo sind Grenzen, wo sind Potenziale? Wie funktionieren die Werkzeuge, die Tonmeistern und Produzenten zur Verfügung stehen? Dieser Artikel gibt einen Einblick hinter die Kulissen der KI-Entwicklung im Audiobereich und evaluiert, welche Auswirkungen auf die Musikindustrie zu erwarten sind.
Block 1
Über die letzten Jahre sind Computer mittels neuer Architekturen und mehr Rechenkapazität in die Lage versetzt worden, Probleme zu bewältigen, deren Lösung sich üblicherweise nur ein Mensch zugetraut hätte. Beim Verarbeiten von Bildern sind KIs vom Unterscheiden zwischen Hund und Katze über das automatische Identifizieren von Personen beim Generieren täuschend echt aussehender Fotos und Videos angekommen. Auf der Textseite können wir nach Rechtschreibkorrektur und Textvervollständigung nun auch komplette Aufsätze, Artikel und mathematische Beweise generieren. Die Vielzahl neuer Anwendungsfälle erweckt schnell den Eindruck, KI laufe in allen Belangen dem menschlichen Intellekt den Rang ab. Doch die meisten KI-Programme verhalten sich in der Regel nur wie Zaubertricks. Hat man diese einmal durchschaut und verstanden, stellt sich eine gesunde Erkenntnis über ihre Stärken und Schwächen ein. Versteht man dann auch noch die Grundbausteine, aus denen die Systeme aufgebaut sind, kann man sie effektiv für sich nutzen.
Es hat vor allem praktische Gründe, warum die meisten bekannten Meilensteine der KI-Entwicklung wie das Generieren von Bildern und Texten, bisher hauptsächlich visueller oder sprachlicher Natur waren. Die Ergebnisse, die KIs mit Bildern und Texten generieren, sind für die meisten Menschen ohne spezielles Equipment einfach zu verstehen und zu beurteilen, und sie sind in ihrer digitalen Repräsentation einfach zu verarbeiten. Dazu kommt, dass Bild- und Textinhalte, mit denen Systeme trainiert werden können, in großem Umfang im Internet frei zugänglich sind. Mit Audio ist das nicht im gleichen Maße der Fall. Die meisten Endkonsumenten können nur schwer beurteilen, was einer schlechten im Vergleich zu einer guten Tonaufnahme fehlt, um dies einem System mitzuteilen. Auf der technischen Seite stellte die hohe Dichte an Informationen, die wir Menschen aus einfachen Schallwellen extrahieren können, Computer lange Zeit vor Probleme. Letztlich sind die meisten Tonaufnahmen auch nicht in beliebiger Qualität frei verfügbar, um ausreichend große, hochqualitative Datensätze zusammenzustellen. Deshalb pflegte die KI-Entwicklung im Audiobereich lange Zeit ein Nischendasein. Das hat begonnen, sich zu ändern.
Erstes Lernen am Beispiel
Um zu verstehen, wie neueste KI-Programme lernen, Audioinhalte zu analysieren oder zu generieren, hilft es, zu betrachten, wie sie entwickelt werden. Nehmen wir dazu als einfaches Beispiel ein Programm, welches das Genre eines aufgenommenen Musikstücks bestimmen soll. Dabei werden wir feststellen, dass die digitale Lösung des Problems gar nicht so weit entfernt von unserer menschlichen Realität ist. Schalten wir Menschen beispielsweise das Autoradio ein, genügen uns in der Regel ein paar Sekunden der gespielten Musik, um ihr Genre zu bestimmen. Die Basis für die Bestimmung ist unsere Erfahrung, welche Instrumente typischerweise in dem Genre vorkommen, und welchen Aufbau und rhythmische Eigenheiten die Stücke haben. Sofern eine KI Aspekte wie die genannten identifizieren kann, ist somit davon auszugehen, dass auch sie anhand eines kurzen Musikschnipsels in der Lage ist, ein Genre zu bestimmen.
.
Nun stellt sich die Frage, wie wir auf Basis unserer Beobachtung im echten Leben ein KI-Modell finden, das angesprochene Aspekte wie Instrumentation, Rhythmus oder Aufbau erkennen kann, wenn wir es mit einer kurzen Tonaufnahme als Eingabe füttern. Hierfür lohnt sich ein Blick in die Welt der Bildklassifizierung. Dort sind Convolutional Neural Networks (CNNs) üblich, um Bilder zu klassifizieren und Objekte in Bildern zu erkennen. CNNs sind eine bestimmte Form neuronaler Netze, in denen Neuronen so miteinander verbunden sind, dass sie bestimmte Merkmale der Eingabe erkennen und hervorheben können. Man kann sich das wie verschiedene Filter oder Schablonen vorstellen, bei denen das CNN lernt, sie auf die eingegebenen Bilder anzuwenden, so wie wir Menschen etwa die Form eines Autos oder einer Flasche erkennen. Mit den Filtern kann das CNN daraufhin Objekte extrahieren und die Konstellation der gefilterten Objekte verstehen. In unserem Fall wollen wir das CNN dazu bringen, bestimmte akustische Filter zu finden, mit denen es instrumentale, rhythmische oder andere strukturelle Aspekte aus der Tonaufnahme isoliert. Wie Abbildung 1 zeigt, kann das CNN diese isolierten Aspekte anschließend über seine Neuronen mit anderen isolierten Aspekten verrechnen und kommt so zu einer Vorhersage, wie wahrscheinlich die Aufnahme jeweiligen Genres entspricht.
Block 3
Abbildung 1: Trainingszyklus unseres CNNs. Das CNN sagt vorher, mit welcher Wahrscheinlichkeit eine Aufnahme den jeweiligen Genres entspricht. Anhand der gepaarten Beispiele aus Aufnahme und tatsächlichem Genre lernt es mit der Zeit, korrektere Vorhersagen zu treffen.
Da CNNs in ihrer Beschaffenheit – insbesondere in Bezug auf die angesprochenen Filter – auf Bildeingaben optimiert sind, müssen die Audioaufnahmen so umgewandelt werden, dass das CNN sie genauso leicht wie ein Bild verarbeiten kann. Eine sehr verbreitete Methode hierfür ist die Berechnung des Betrags der schnellen Fourier-Transformation des Eingangssignals. Umgangssprachlich spricht man hier vom Spektrogramm der Aufnahme, wie man es zum Beispiel aus Restaurationssoftware wie iZotope RX kennt. Wer öfter Spektrogramme begutachtet, versteht, wie man Instrumente, Rhythmus und andere Bestandteile einer Aufnahme darin erkennen kann. Letzteres wird auch unser CNN lernen, indem wir es entsprechend trainieren. Dafür benötigen wir einen existierenden Datensatz, der sowohl aus Tonaufnahmen oder deren Spektrogramm besteht, und deren tatsächliche Genre-Klassifizierung, die beispielsweise von einem Menschen vorgenommen wurde. Typischerweise sind hier Datensätze in der Größenordnung mehrerer zehntausend bis hunderttausend Beispiele nötig, um stabile Ergebnisse zu erzielen.
Für das Training werden die Spektrogramme der Aufnahmen in unserem Datensatz dem CNN paketweise, in sogenannten Batches, als Eingabe verabreicht. Die vom CNN vorhergesagten Wahrscheinlichkeiten, dass die Aufnahmen in dem Batch einem jeweiligen Genre entsprechen, werden anschließend mit der tatsächlichen Genreklassifizierung aus dem Datensatz, Ground Truth genannt, verglichen. Aus der Abweichung der Vorhersage des CNNs vom tatsächlich richtigen Genre wird daraufhin über ein Verfahren namens Back Propagation berechnet, wie das CNN seine einzelnen Neuronen im Inneren aktualisieren muss, damit es beim Begutachten des nächsten Batch mit höherer Wahrscheinlichkeit das richtige Genre ausgibt. Dieser Prozess, in Abbildung 1 dargestellt, wiederholt sich über mehrere Iterationen, sogenannte Epochen, auf dem Trainingsdatensatz. Da es noch keinen Zusammenhang zwischen einer Tonaufnahme und dem korrekten Genre kennt, wird das CNN zu Beginn sinnlose Wahrscheinlichkeiten angeben. Nach und nach wird es allerdings verstehen, auf welche Aspekte in den Tonaufnahmen es seinen Blick, also seine Filter und Neuronen, schärfen muss, um eine hohe Wahrscheinlichkeit für das richtige Genre auszugeben. Tritt diese Erkenntnis ein, spricht man davon, dass das CNN konvergiert. Da es dabei selbst seine Neuronen im Inneren anpasst und ein nach außen hin verstecktes Verständnis dafür entwickelt, wie es unsere Aufgabe lösen kann, nennt man den Lernprozess Deep Learning. Da wir dem Modell explizite Lernbeispiele aus Eingabe, dem Spektrogramm, und erwarteter Ausgabe, dem richtigen Genre, präsentieren, spricht man zudem von Supervised Learning. Sofern unser Datensatz repräsentativ für andere Tonaufnahmen ist, ist unser CNN nach dem Training in der Lage, das Genre unbekannter Aufnahmen in Sekunden treffsicher zu klassifizieren, sofern sie in eines der gelernten Genres fallen.
Der Schritt zu Generative AI
So wie wir unserem CNN beigebracht haben, bestimmte Musikgenres vorherzusagen, könnte man es auf ähnliche Weise trainieren, um andere musikalische Aspekte zu verstehen, wie zum Beispiel Stimmung, Tempo oder Timbre. Wie aber schafft man es, dass eine KI selbst zum Komponisten wird? Auch hier ist die analoge Wirklichkeit das Vorbild des digitalen Vorgehens. Als Menschen lernen wir in der Schule von unseren Lehrern, Aufgaben so zu erledigen, wie es von uns verlangt wird. Sind wir lernwillig und fleißig, werden wir mit der Zeit immer besser darin, Anforderungen zu erfüllen. Primitiv betrachtet kann man von einem Spiel sprechen, in dem wir als Lehrlinge so lange neue Abgaben abliefern, bis die Lehrkraft zufrieden ist und uns in den Ernst des Lebens entlässt. Dieses Prinzip wird auch in der KI-Entwicklung genutzt: Ein Modell spielt die Lehrkraft, das sogenannte Discriminator-Modell, und ein anderes den Lehrling, das sogenannte Generator-Modell. Das Discriminator-Modell wird ähnlich wie unser Genre-CNN darauf trainiert, ein echtes Musikstück von einem maschinengenerierten Musikstück zu unterscheiden. Gleichzeitig versucht das Generator-Modell, neue Musikstücke zu generieren, die das Discriminator-Modell fälschlicherweise für echt hält. Die beiden treten in ein Wettrennen ein, wie in Abbildung 2 dargestellt. Das Generator-Modell wird immer besser darin, das Discriminator-Modell auszutricksen und von seinen Musikstücken zu überzeugen, und das Discriminator-Modell wird immer besser darin, die nicht menschlichen Musikstücke des Generator-Modells zu erkennen. Daraufhin muss das Generator-Modell wieder besser im Komponieren werden, um das Discriminator-Modell weiterhin erfolgreich auszutricksen; umgekehrt muss das Discriminator-Modell wieder besser im Unterscheiden werden, sodass der Kreislauf von vorne beginnt. Der Zyklus wiederholt sich so lange, bis das Generator-Modell in der Lage ist, tatsächlich täuschend echte Musik zu generieren. Anders als bei Menschen, die jahrelang zur Schule gehen, dauert dieses Training nur einige Stunden. Die Modelle, die diese Form von Generative AI umsetzen, werden Generative Adversarial Networks (GANs) genannt. Da GANs über den Wettbewerb mit dem Discriminator-Modell selbst lernen, was brauchbare Ausgaben des Generator-Modells sind, spricht man hier von Unsupervised Learning. Im Musikbereich hat zum Beispiel das Team der Sony Computer Science Labs erfolgreich GANs trainiert, um in Bruchteilen einer Sekunde täuschend echte Drum Samples zu generieren.
Abbildung 2: Trainingszyklus von GANs. Das Generator-Modell wird immer besser darin, das Discriminator-Modell mit generierten Aufnahmen zu überlisten, während das Discriminator-Modell immer besser darin wird, die Täuschung gegenüber echten Aufnahmen zu erkennen.
In der Praxis haben GANs oft die Einschränkung, dass sie nur spezielle Inhalte zuverlässig generieren können, sie beispielsweise nur darauf spezialisiert sind, Gesichter von Personen zu generieren oder, wie erwähnt, Drum Sounds zu produzieren. Grund dafür ist unter anderem der zu bestimmende schmale Pfad an Inhalten, auf dem das Generator-Modell sinnvolle Inhalte produziert, und auf dem das Discriminator-Modell zuverlässig den Inhalt beurteilen kann. Der Sprung für das Generator-Modell, aus dem Nichts etwas Sinnvolles zu generieren, wird schnell zu groß, wenn verschiedene Inhalte generiert werden sollen. Aber auch diese Problematik wurde mittlerweile mithilfe eines Tricks gelöst: Neue Modelle wie Stable Diffusion oder Dall·e wurden darauf trainiert, schrittweise künstliches Rauschen aus Bildern herauszurechnen. Womit es das künstliche Rauschen ersetzen soll, lernt das Modell durch die Ähnlichkeit des entrauschten Bildes zu einer Textbeschreibung des Originalbildes. Führt man diesen Prozess ad absurdum, kann das Modell Schritt für Schritt aus künstlichem Rauschen (also aus dem Nichts) und einer Texteingabe ein Bild generieren. Genauso funktioniert es auch mit Musik: Das Modell Riffusion verwendet denselben Ansatz, um Musikstücke nach Textvorlage zu generieren. Dies geschieht wieder mit dem Vorgehen, Musikaufnahmen mittels Spektrogramms wie Bilder zu behandeln, wie in Abbildung 3 gezeigt.
Keine Daten, kein Problem?
Quelle: Forsgren, Seth and Martiros, Hayk, 2022
Abbildung 3: Musikgenerierung mit Riffusion. Schritt für Schritt erzeugt das Modell das Spektrogramm einer Musikaufnahme zu der Texteingabe „funk bassline with a jazzy saxophone solo“. Das finale Spektrogramm wird dann wieder zurück in ein Zeitsignal umgewandelt. Quelle: Forsgren, Seth and Martiros, Hayk, 2022. „Riffusion – Stable diffusion for real-time music generation.“
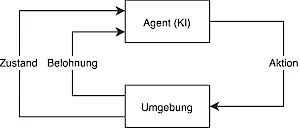
Unabhängig von der gewählten Architektur haben die präsentierten Ansätze eines gemeinsam: Sie benötigen Unmengen an Daten, die für das Training erforderlich sind. Das stößt auf urheberrechtliche und ethische Probleme. Gerade bei großen Modellen ist es schwer, eine hohe Datenqualität zu gewährleisten und zu verifizieren, dass alle Daten aus rechtmäßigen Quellen stammen. Darüber hinaus ist nach dem Training nicht mehr nachvollziehbar, auf Basis welcher Daten ein Modell gelernt hat, bestimmte Ausgaben zu generieren. Gleichzeitig ist es schwer, vorherzusagen, wie viele neue Daten ein Modell braucht, um etwaige Fehler zu korrigieren, oder um neue Fähigkeiten zu lernen. Transparent AI ist deshalb ein neuer Fokus in der KI-Forschung, der darauf abzielt, die gelernten Strukturen in Deep-Learning-Modellen verständlich offenzulegen, um deren Entscheidungen besser nachvollziehen zu können. Verfolgt wird dieser Fokus allerdings primär in akademischen Kreisen, da sich wirtschaftlich noch keine direkten Vorteile daraus ableiten lassen und rechtliche KI-Rahmenbestimmungen fehlen. Dennoch gibt es für bestimmte Probleme eine Alternative zu großen Trainingsdatensätzen mithilfe des Reinforcement Learning. Hierbei lernt eine KI, meist allgemeingültiger „Agent“ genannt, nicht anhand vieler Beispiele, sondern anhand mathematischer Belohnungsfunktionen, eine Aufgabe zu lösen. Diese Funktionen vermitteln dem Agenten, welche Zustände für ihn erstrebenswert sind und welche Zustände er vermeiden soll. Möchte man etwa einem Roboter beibringen zu laufen, kann man eine Belohnungsfunktion implementieren, die einer KI für die entsprechende Motorik immer einen hohen Belohnungswert ausspricht, wenn der Roboter sich aufrecht fortbewegt. Die KI lernt ähnlich wie ein Kind, wie sie diesen Zustand erreicht, wie Gelenke und Motoren zu steuern sind, um aufrecht zu gehen. Dies alles passiert, ohne dass die KI jemals mit Beispielen anderer Gelenk- oder Motoreinstellungen anderer laufender Roboter konfrontiert wurde.
Abbildung 4: Der Feedbackkreislauf im Reinforcement Learning. Ein intelligenter Agent lernt, welche Aktionen er in welchem Zustand in seiner Umgebung ausführen muss, um seine Belohnung zu maximieren.
Die Vorteile des Reinforcement Learnings sind erheblich, denn man kann klar definieren, welche Szenarien herbeigeführt oder verhindert werden sollen, und durch kontinuierliche Verbesserung der Belohnungsfunktionen verbessert sich auch die KI fortwährend weiter. Die Schwierigkeit besteht in der mathematischen Definition der Belohnungen, da nicht für alle Probleme offensichtlich ist, auf welche Aspekte hin optimiert wird. Im Musikbereich ist „Masterchannel“ wohl deshalb auch eine der wenigen prominenten Plattformen, die diesen Ansatz erfolgreich im Mastering verfolgen, wie im Artikel „KI als Masteringwerkzeug“ beschrieben.
Die Musikindustrie am Wendepunkt
Aus den gezeigten Beispielen wird ersichtlich, dass KI-Musik in ihrem Entstehungsprozess nicht dieselben Phasen durchläuft wie von Menschen gemachte Musik. Auf diese Aspekte berufen sich KI-Kritiker gern, wenn sie ihre Arbeit als Kunsthandwerk verteidigen. Natürlich liegt der Wert und Sinn von Kunst und Musik mitunter im Entstehungsprozess. Viele dieser Kritiker haben die meisten KI-Tools allerdings noch nicht selbst ausprobiert, um sich eine qualifizierte Meinung zu bilden, und es ist fraglich, ob solche Plädoyers am Ende überhaupt Gewicht haben. Der wirtschaftliche Vorteil guter KIs ist nicht von der Hand zu weisen. Warum sollte ein Label Künstler bezahlen, die Musik für Workout Playlists auf Spotify produzieren, wenn eine KI die passende Musik en masse liefert? Warum sollte ein Musikhörer nach Künstlern für das Candlelight-Dinner suchen, wenn eine KI personalisierte Musik für den Abend komponiert? Es stellt sich nicht mehr die Frage ob, sondern wann die Technologie die Musikindustrie vor vollendete Tatsachen stellt. Auf die Moral und Wertschätzung der Massen sollte man dabei nicht bauen, wie uns das Streaming-Zeitalter schon lehrte. Letztlich gewinnt die Bequemlichkeit der Konsumenten.
Unstrittig ist, dass KIs uns in unserer Produktivität und in der technischen Ausführung überholen. Erfolgreiche Künstler, die die neue Realität erkannt haben, wechseln deshalb auf die Seite der Technologie, um sich im Wettbewerb zu behaupten. Anstatt ihre Zeit mit rein technischen Prozessen zu vergeuden, integrieren sie KIs in ihre Workflows, um mehr Raum für Kreativität zu schaffen. Am Ende gewinnen damit alle: Die Endergebnisse sind frischer, schneller fertiggestellt und kostengünstiger. Im Artikel „KI als Masteringwerkzeug“ beleuchten wir, wie das im Mastering schon funktioniert, sogar zum überraschenden Vorteil menschlicher Mastering Engineers.
Vielleicht steht uns am Ende eine Entwicklung bevor, die der von Spotify ähneln könnte. Die Industrie sträubte sich, eine neue Realität des Streamings zu akzeptieren, obwohl der Wandel schon in vollem Schwung war. Schlussendlich profitieren diejenigen, die sich rechtzeitig damit befassten, und die großen Player wechselten hinter den Kulissen das Pferd. Diesmal sind die Barrieren jedoch denkbar niedrig, sodass sich jeder mit den neuen Werkzeugen vertraut machen und davon profitieren kann. Als Kreativschaffende zu einer starken Nutzergruppe neuer Technologien zu werden, ist der vielversprechendste Weg, deren Entwicklung in unserem Sinne mitzugestalten.
Der Autor
Simon Hestermann ist CTO und Mitgründer von Masterchannel, einem norwegischen KI-Startup für Audiomastering. Er schloss sein Informatikstudium am King’s College London mit Auszeichnung ab und entwickelte am Fraunhofer IDMT ein patentiertes Verfahren für objektbasiertes Mastering. Nebenbei arbeitete er als Freelance Mastering Engineer für Künstler wie James Carter und Tyler Ward.