Rückblick: Stand der Forschung 11 Jahre vor dem Start von DAB in Deutschland
Historischer Tagungsbeitrag von Günther Theile und Gerhard Stoll aus dem Jahre 1988
Text and Images: Günther Theile, Gerhard Stoll
Text and Images: Günther Theile, Gerhard Stoll
Der VDT führt ein Archiv mit alten Schriften zu den vergangenen Tonmeistertagungen. Dieses haben wir anlässlich des 75-jährigen Verbandsjubiläums durchforstet und dabei wahre Schätze geborgen. Viele Artikel waren schlichtweg visonär und haben sich aus heutiger Sicht als wegweisend erwiesen. Eigentlich hätten wir guten Gewissens auch ein ganzes VDT-Magazin damit füllen können; zumindest zwei davon möchten wir euch hier vorstellen.
Den Einstieg macht ein Artikel von Günther Theile und Gerhard Stoll. In diesem wird die gehörangepasste Quellencodierung für digitalen Rundfunkt dargelegt. Erschienen ist das Papier zur 15. Tonmeistertagung in Karlsruhe 1988 – also zu einer Zeit, zu der der VDT und das Neumann M 50 noch keine 40 Jahre alt waren, als Digitalanzeigen bei einem Radio noch als ultimativer Luxus zählten, bevor Streaming überhaupt denkbar war und bis zur Einführung des DAB-Rundfunks in Deutschland noch elf weitere Jahre ins Land ziehen sollten.
Im Text ist die Rede von MASCAM, welches durch MUSICAM beerbt wurde – das als psychoakustisches Reduktionssystem in MPEG-1, Layer 2 („MP2“) verwendet wird. Was heute, da MP3 & Co. schon vor Jahren in jedermanns täglichen Gebrauch übergegangen sind, als Grundlage gelehrt wird, mag 1988 auf manchen vornehmlich mit Analogmischpult und Bandmaschine werkelnden Tonmeister vielleicht noch reichlich abstrakt gewirkt haben. Und so liest sich „Terrestrischer Digitaler Hörrundfunk“ auch heute noch wie eine solide Themeneinführung, wenngleich sich die Reduktionssysteme fortentwickelt haben.
Die Artefakte bei Fehlern in der Übertragungskette sind heutzutage auch dem Endnutzer bekannt. Unter „Unempfindlichkeit der Abtastwerte gegenüber Bitfehlern“ findet man den Satz: „In diesem Fall arbeitet das Verfahren ähnlich einem 24-Kanal-Vocoder mit amplitudenmoduliertem Teilbandrauschen und kann damit auch in einem sehr hohen Fehlerfall zumindest Sprachverständlichkeit garantieren.“
Die Forschungsarbeit von Günther Theile und Gerhard Stoll war wegweisend. Unser Verband profitierte in besonderem Maße von Günthers Mitgliedschaft: Er hat über Jahrzehnte die Programme der Tonmeistertagungen kuratiert, war Vorstandsmitglied und erhielt mit der Ehrenmitgliedschaft (2019) und der VDT-Ehrenmedaille (2023) die höchsten VDT-Würden.
Hinweis: Die Orthographie und Zeichensetzung des Artikels wurden originalgetreu beibehalten.
– die Redaktion

Ein digitales terrestrisches Hörrundfunksystem muss erhebliche Vorteile gegenüber dem bisherigen UKW-FM-Rundfunk aufweisen. Hierbei werden unter anderem sehr hohe Anforderungen an eine Quellencodierung des Audiosignals gestellt. Diese betreffen die folgenden wesentlichen Merkmale eines digitalen terrestrischen Hörrundfunksystems:
I. Audio-Qualität
Sie sollte dem heutzutage erreichbaren Standard entsprechen, wie er z. B. durch die Compact Disc gegeben ist.
II. Großes Programmangebot
Im UKW-FM-Rundfunk lassen sich nur 4 - 5 Programme flächendeckend verteilen. Ein Hörer kann neben diesen eventuell noch lokale Sender und – mit eingeschränkter Qualität – entferntere Sender aus anderen Versorgungsbereichen empfangen. Ein ausreichendes Programmangebot sollte eine Vielzahl von Programmen auch von entfernteren Programmanbietern in unterschiedslos gleich guter Qualität enthalten.
Ill. Mobiler Empfang
Der Empfang im fahrenden Kraftfahrzeug sollte wesentlich besser sein als der z. Z. mögliche Empfang beim UKW-FM-Rundfunk. Dazu gehört neben der Verbesserung des Signal-Rausch-Verhältnisses im Audiobereich auch die Unterdrückung kurzzeitiger Störungen durch z. B. mangelhafte Zündanlagen sowie die Überbrückung von längerfristigen Störungen, bzw. Ausfällen des Signales im Bereich von etwa 100 ms, wie sie z. B. bei extrem ungünstigen Empfangsbedingungen, wie Brückendurchfahrten, Mehrwegeempfang und extrem schwankendem Signal-Rausch-Verhältnis des HF-Signals gegeben sind.
Diese drei Merkmale erfordern eine Quellencodierung, die bei einer äußerst geringen Datenrate von nur etwa 100 kbit/s pro Monokanal eine gleiche subjektive Qualität ermöglicht, wie sie durch eine Abtastung des Audiosignals mit 44.1 kHz und einer Auflösung der einzelnen Abtastwerte von 16 Bit, d.h. bei einer Datenrate von 705 kbit/s gegeben ist (siehe l. Merkmal).
Zusätzlich werden, vor allem durch das 3. Merkmal, hohe Anforderungen an eine im Verfahren selbst enthaltene Unempfindlichkeit gegenüber Übertragungsstörungen („inhärenter Fehlerschutz“) und an zusätzliche Maßnahmen zur Fehlerverschleierung gestellt.
Für eine digitale Übertragung, bzw. Speicherung von hochqualitativen Tonsignalen befinden sich derzeit mehrere Quellencodierverfahren in der Entwicklung, die eine bemerkenswerte Reduktion der Datenrate im Vergleich zu einer Codierung im 16-Bit-linear Format ermöglichen. Bei den derzeitigen Verfahren bewegen sich die typischen Datenraten für die Codierung eines Monokanals im Bereich von 64 - 136 kbit/s (Quellen: 1, 2, 3, 4, 5).
Trotz einer erheblichen Reduktion der Datenrate sind meist keine, oder nur äußerst geringe Qualitätsverluste durch das Gehör wahrnehmbar. Einer der wichtigsten Aspekte all dieser Verfahren ist die Reduktion der Irrelevanz und der Redundanz, die mehr oder weniger in jedem Tonsignal enthalten sind. Diese Reduktion führt zu ganz spezifischen Fehlern, die dem originalen Tonsignal jedoch so überlagert werden, daß sie vom Gehör nicht wahrgenommen werden können. Diese Fehler werden spektral und zeitlich so geformt, daß sie durch das Originalsignal maskiert werden. Dies ist möglich, da das Gehör nur ein begrenztes spektrales und zeitliches Auflösungsvermögen besitzt.
Anhand des MASCAM-Verfahrens (Masking-pattern Adapted Subband Coding And Multiplexing) (Quellen: 1, 6, 7, 8) wird im folgenden gezeigt, daß die bezüglich des eigentlichen Empfängers „Gehör“ geforderte Genauigkeit der Signaldarstellung abhängig vom spektralen und zeitlichen Verlauf des Tonsignals meist überraschend gering ist. Eine konsequente Berücksichtigung der Maskierungsverhältnisse führt in der Tat zu sehr geringen Datenraten, die in Abhängigkeit vom Tonsignal zeitlich schwanken.
Übliche PCM-Systeme erzeugen näherungsweise ein weißes Quantisierungsrauschen, das der Forderung „möglichst unhörbar“ bei geringer Quantisierung nicht entspricht (Quelle: 9). Aus diesem Grund ist mit breitbandig arbeitenden Kompandersysternen nur eine geringe Reduktion der Datenrate möglich, ohne daß Quantisierungsfehler vom Gehör wahrgenommen werden. Die neuen Quellencodierverfahren für hochwertige Tonsignalübertragung bei hoher Datenreduktion nutzen die Möglichkeit, die Quantisierungsfehler der Selektivität des Gehörs anzupassen.
Alle derzeitigen Verfahren beruhen auf einer spektralen und zeitlichen Zerlegung des Tonsignals mit einer anschließenden frequenz- und zeitabhängigen Zuweisung der Quantisierung. Diese spektrale Zerlegung kann sowohl durch eine digitale Filterbank (Teilbandcodierung), als auch durch eine diskrete Fourier- oder Cosinustransformation (Transformationscodierung) realisiert werden.
Eine wesentliche Eigenschaft dieser Codierungsform besteht darin, daß ein Block zeitlich aufeinanderfolgender Abtastwerte mittels einer FFT (Fast Fourier Transform) oder DCT (Discrete Cosine Transform) in den Spektralbereich überführt werden (Quellen: 2, 3, 5). Die Transformationscodierung an sich ist zunächst ein Verfahren, um die Redundanz eines Signals zu reduzieren. Der theoretische Gewinn an Signal/Rauschverhältnis gegenüber üblichen PCM-Systemen ist abhängig von den Eigenschaften des Tonsignals, der Transformationsform und ihrer Blocklänge, sowie von der verwendeten Fensterfunktion. Eine zusätzliche Datenreduktion kann in Form einer Verminderung der Irrelevanz erfolgen, indem die Quantisierung abhängig von der Maskierung des Quantisierungsrauschen vorgenommen wird.
Für die Übertragung mit einer geringen Übertragungsrate werden die Stützwerte der Amplitude und Phase von Block zu Block mit einer minimal erforderlichen Genauigkeit, die durch die Maskierungseffekte des Gehörs gegeben ist, aufgelöst. Dieser Prozeß wird als „dynamische Bitzuweisung“ bezeichnet und ist sehr stark abhängig von der Beschaffenheit der zu übertragenden Musik- oder Sprachsignale.
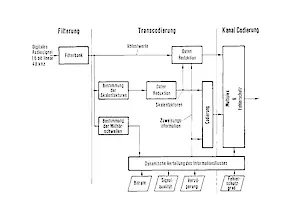
Bei dieser Codierungsform wird das digitale Tonsignal mittels einer geeigneten digitalen Filterbank, z.B. QMF oder NWDF (Quellen: 10, 11, 12) in eine gewisse Anzahl (typischerweise 12 bis 24) Teilbänder unterteilt. Nach der spektralen Zerlegung des Tonsignals wird für einen Block aufeinanderfolgender Abtastwerte ein sogenannter Skalenfaktor gebildet, der ein Maß für den maximalen Pegel in jedem Teilband darstellt. Die Abtastwerte aller Teilbänder werden anschließend einer Datenreduktion (Transcodierung) unterworfen.
Diese Reduktion erfolgt z. B. bei MASCAM aufgrund der Berechnung der Mithörschwelle (Quelle: 13) des zu codierenden Signals. Der Grad der Reduktion wird für jedes Teilband und jeden Block aufeinanderfolgender Abtastwerte individuell von der Kontrollstufe „dynamische Bitzuweisung“ (siehe Abb.1) gesteuert.
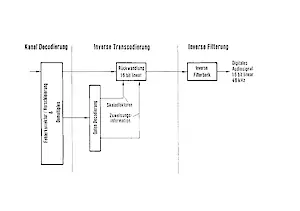
Empfangsseitig wird durch inverse Transcodierung und Filterung ein 16-Bit-linear-codiertes Tonsignal zurückgewonnen. Abb.2 zeigt den gesamten Prozeß, der zur Decodierung des Signals erforderlich ist. Die inverse Transcodierung erfolgt wie die empfangssei tige Transcodierung abhängig von der Steuerinformation, die in der senderseitigen Kontrollstufe „dynamische Bitzuweisung“ berechnet und zusammen mit den Skalenfaktoren als Nebeninformation übertragen wird. Aufgrund der Übertragung der Zuweisungsinformation vereinfacht sich der Aufwand im Decoder erheblich, d. h. die wesentliche Prozessorleistung bleibt auf die Filterbank beschränkt.
Die Grundlage der lrrelevanzreduktion ist die Berechnung der spektralen und zeitlichen Mithörschwellen des Gehörs aufgrund des aktuellen Tonsignals. Für das Beispiel eines Vokals a ist eine solche Schwelle für einen bestimmten Zeitpunkt in Abb. 3 dargestellt. Die Teiltonpegel sind als Punkte, die Ruhehörschwelle gestrichelt, die Mithörschwelle als ausgezogene Kurve und die Teilbandgrenzen der Filterbank durch senkrechte Linien dargestellt. Der Effekt der Maskierung führt zu zwei Konsequenzen, die beim MASCAM-Verfahren wie folgt genutzt werden. Zum einen werden solche Teilbänder, die Teiltöne beinhalten, die unterhalb der Mithörschwelle liegen, nicht übertragen und beanspruchen somit keine Informationskapazität. Zum anderen kann die Quantisierung in den einzelnen Teilbändern so gesteuert werden, daß die auftretenden Verzerrungen sich immer unterhalb der aktuell wirksamen Mithörschwelle befinden , wie in Abb. 3 beispielhaft dargestellt.
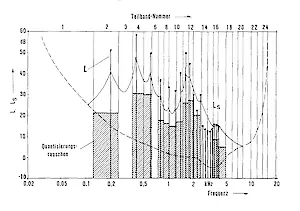
Die dynamische Bitzuweisung für die notwendige Quantisierung in den einzelnen Teilbändern ist abhängig vom Signal- und Mithörschwellenverlauf. Diese Zuweisung ist normalerweise dadurch gekennzeichnet, daß der Abstand zwischen Mithörschwelle und Quantisierungsfehler in den Teilbändern möglichst gleich, d. h. frequenzunabhängig ist. Somit resultiert für die Codierung von zeitvarianten Tonsignalen eine dynamische Bitrate, die von der spektralen und zeitlichen Struktur des Tonsignals abhängt (Quelle: 8).
Schmalbandige Signale benötigen eine geringe Datenrate, da in einem solchen Fall viele Teilbandsignale nicht übertragen werden müssen. Im Gegensatz dazu benötigen breitbandige Signale, vor allem solche mit ausgeprägten Pegeln im Bereich höherer Frequenzen eine weitaus höhere Bitrate. Mit einer Bitrate von 110 kbit/s einschließlich der Nebeninformation können auch besonders kritische, d.h. stationäre, breitbandige tonale Signale, deren Teiltonabstand in etwa den Bandbreiten der Teilbänder entspricht, ohne subjektive Qualitätsverluste im Vergleich zu einer Codierung im 16-bit-Format übertragen werden. Im Falle von natürlichen Mikrofonsignalen ist die notwendige Bitrate jedoch meist erheblich geringer. Mit einem zusätzlichen Pufferspeicher können die kurzzeitig auftretenden maximalen Bitraten gemindert werden, d. h. der Bitratenverlauf über der Zeit wird mit zunehmender Speichertiefe ausgeglichener. Mit einer Verzögerungszeit von 40 ms verringert sich die maximale Datenrate um etwa 10 kbit/s.
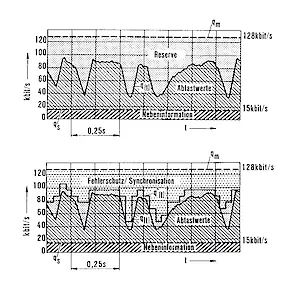
Da einerseits die für die Codierung des Signals notwendige Datenrate signalabhängig schwankt, andererseits das Multiplexsignal am Ausgang des Coders jedoch einen konstanten Datenstrom erfordert, steht eine sogenannte „dynamische Bitflußreserve“ (Quelle: 8) zur freien Verfügung. In Abb.4 sind exemplarisch die benötigten Bitraten q(t) für die Abtastwerte (Beispiel: Sprache) und eine konstante Datenrate qs = 15 kbit/s für die Nebeninformation dargestellt. Diese besteht aus der information und den Skalenfaktoren für die einzelnen Quantisierungs-Teilbänder. Die Differenz aus qm - q(t), dargestellt als punktierte Fläche, kennzeichnet die dynamische Bitflußreserve. Diese variiert in Abhängigkeit vom Tonsignal im Bereich von etwa 30 ...100 kbit/s, wenn die konstante Bitrate des MASCAM-codierten Signales mit qm = 128 kbit/s angenommen wird. Mit dieser Reserve sind folgende Anwendungsmöglichkeiten denkbar:
Übertragung von zeitunkritischen Zusatzinformationen wie z. B. Programminformation, Radiotext oder Verkehrsfunk.
Höhere Quantisierung in den einzelnen Teilbändern, um einen größeren Abstand zwischen Quantisierungsrauschen und Mithörschwelle zu erreichen. Bei einer minimalen Quantisierung, d.h. Annäherung ser Mithöschwelle durch das Quantisierungsrauschen, kann sich eine subjektive Beeinträchtigung eines codierten Signales aufgrund von Frequenzgangverzerrungen (z.B. Equalizer im Empfänger) ergeben, da die spektralen Maskierungsverhältnisse durch solche Maßnahmen verändert werden.
Dynamischer Bitfehlerschutz, um einen höheren Fehlerschutz von solchen Signalanteilen zu realisieren, die eine besonders hohe subjektive Störwirkung bei Übertragungsfehlern aufweisen. Ein Teil der Bitrate des Multiplexsignals läßt sich dabei für die Kanalcodierung, d.h. für den Bitfehlerschutz der übertragenen Daten benutzen. Die dynamische Bitflußreserve kann nun für die Kanalcodierung zur Verbesserung des Fehlerschutzgrades abhängig von der gerade zur Verfügung stehenden Reserve verwendet werden. Dies wird als dynamischer Fehlerschutz /6/ bezeichnet und ist in Abb.4 (unten) dargestellt. Typischerweise können besonders solche Signale, die eine relativ geringe Bitrate benötigen (in der Regel schmalbandige, bzw. leise Signale, bei denen Bitfehlerstörungen sehr stark wahrnehmbar sind), mit einem hohen Bitfehlerschutz versehen werden. Ein MASCAM-codiertes Signal enthält damit einen effektiven "inhärenten Fehlerschutz", weil empfindliche Signalanteile besonders wirksam geschützt werden, ohne dabei die Bitrate wesentlich zu erhöhen.
Der mobile Empfang von digitalen Hörfunkprogrammen stellt sehr hohe Anforderungen an die Unempfindlichkeit eines Quellencodierverfahrens gegenüber Übertragungsstörungen. Hierbei müssen die Maßnahmen der Kanalcodierung sehr sorgfältig sowohl auf den Übertragungskanal mit seiner typischen Fehlerstruktur, als auch auf das verwendete Quellencodierverfahren abgestimmt werden (Quelle: 14). Nur damit wird es möglich sein, eine minimale Gesamtübertragungsrate durch eine äußerst gezielte Einfügung der Redundanz für die Fehlerkorrektur und -verschleierung zu realisieren. Um die Unempfindlichkeit gegenüber Bitfehlern zu optimieren, sollten die folgenden drei Aspekte berücksichtigt werden.
Beim MASCAM-Verfahren bewirken Bitfehler der Abtastwerte keine breitbandigen Knackstörungen, denn diese sind aufgrund der Unterteilung des Tonsignals in einzelne Teilbänder auf das Teilband beschränkt, in dem eine Bitfehlerstörung auftritt (Quelle: 6). Da die Bandbreiten des MASCAM-Verfahrens näherungsweise den Frequenzgruppen des Gehörs entsprechen, ist zudem die Lautstärke der auftretenden Störungen optimal begrenzt. Darüberhinaus wird die maximale Amplitude eines Bitfehlers durch den Skalenfaktor unter der Voraussetzung eingeschränkt, daß allein die Skalenfaktoren der einzelnen Teilbänder so geschützt sind, um diese fehlerfrei übertragen zu können. Dies bedeutet, daß Bitfehler mit einer Fehlerrate von 10-3 zwar ein gerade eben wahrnehmbares Bitfehlerrauschen erzeugen, das jedoch noch nicht störend ist.
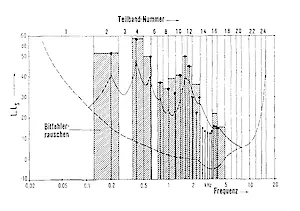
Um dies zu verdeutlichen, wird eine Situation angenommen, in der alle Abtastwerte gänzlich gestört und nur die Skalenfaktoren einwandfrei übertragen werden. In diesem Fall ist zwar die tonale Information, d.h. die Information über die Tonhöhe, nicht mehr vorhanden, jedoch wird die spektrale Hüllkurve des Nutzsignals näherungsweise durch das Bitfehlerrauschen angeglichen (siehe Abb. 5). In diesem Fall arbeitet das Verfahren ähnlich einem 24-Kanal-Vocoder mit amplitudenmoduliertem Teilbandrauschen und kann damit auch in einem sehr hohen Fehlerfall zumindest Sprachverständlichkeit garantieren. Die einzige Voraussetzung hierfür ist, daß während der gestörten Übertragung kein Verlust an Skalenfaktoren und Synchronbits auftreten darf.
Durch einige Experimente wurde herausgefunden, daß zusätzlich zu den Skalenfaktoren und der Quantisierungsinformation für die einzelnen Teilbänder nur die wichtigsten Bits (MSBs) der unteren Teilbänder zu schützen sind. Das bedeutet, daß mit gezielten Maßnahmen ein für das Gehör äußerst effizienter Fehlerschutz zu realisieren ist.
Aus den Forschungsergebnissen zur Tonhöhen- und Sprachwahrnehmung ist bekannt, daß es sogenannte dominante Frequenzbereiche gibt. So unterscheidet man bei der Tonhöhe zwischen dem dominanten Frequenzbereich der Spektraltonhöhe (ca. 0.5 bis 1.55 kHz) und der Virtuellen Tonhöhe (bis ca. 0.5 kHz) (Quelle: 5). Dies bedeutet, daß die wesentliche Information über die Tonhöhe eines Tonsignals im Frequenzbereich unter 2 kHz liegt. Verständlichkeitsmessungen mit hoch- und tiefpaßbegrenzten Sprachlauten (Quelle: 16) zeigten ebenfalls, daß es für die Verständlichkeit von Sprache einen dominanten Frequenzbereich gibt, der ziemlich genau mit dem Bereich der Spektraltonhöhe übereinstimmt.
Aus diesem Grunde ist es sinnvoll, die für die Tonhöhenwahrnehmung und Verständlichkeit besonders wichtigen Bereiche stärker gegenüber Übertragungsfehler zu schützen als andere, unwichtigere Bereiche. Ein Schutz der beiden MSBs der Abtastwerte der Teilbandsignale im Bereich bis zu 1 kHz und nur des MSBs allein im Bereich von 1 ... 2 kHz erwies sich dabei als äußerst effektiv. In diesem Fall müssen nur 6 kbit/s zusätzlich mit Redundanz versehen werden.
Nachdem diese „wichtigen Bits“ genauso geschützt wurden wie die Skalenfaktoren und die Quantisierungsinformation, konnte mit dieser Maßnahme die Bitfehlerrate von 10-3 auf über 10-2 erhöht werden, ohne daß aufgrund der höheren Fehlerrate eine stärkere Beeinträchtigung des Signals wahrnehmbar war.
Im Ganzen enthält das MASCAM-Multiplexsignal eine geringe Anzahl von nur etwa 20 % sehr wichtiger und daher besonders schützenswerter Bits, während der überwiegende Teil der Daten kaum Redundanz für einen Fehlerschutz erfordert.
Wie schon in Kapitel 4.2 dargelegt wurde, stellt der dynamische Bitfehlerschutz eine wirksame Maßnahme dar, um die Bitfehlersicherheit zu vergrößern. Zunächst werden alle wichtigen Bits mit einem konstanten und sehr effektiven Schutz versehen, während die restlichen Bits mit einem dynamischen Schutz, in Abhängigkeit der Rangfolge der Wichtigkeit der Bits, versehen werden. Damit kann eine hohe subjektive Übertragungsqualität auch bei sehr hohen Bitfehlerstörungen erzielt werden.
Die Strategien zur Kanalcodierung sollten nicht nur den Übertragungskanal und das zu erwartende Störverhalten allein berücksichtigen, sondern sie sollten auch bezüglich der Eigenschaften des codierten Tonsignals ausgewählt werden. Das bedeutet, daß die Kanalcodierung ein Höchstmaß an Nutzen aus der Quellencodierung ziehen sollte. Wie schon zu Beginn von Kap. 5 gezeigt wurde, weisen MASCAM-codierte Tonsignale einen hohen Grad an Bitfehlerunempfindlichkeit auf. Untersuchungen zu einer quellenadaptiven Kanalcodierung für die Übertragung von Sprachsignalen liegen bereits vor (Quelle: 14) und werden derzeit bezüglich einer Anwendung bei allgemeinen Tonsignalen weitergeführt (Quelle: 17). Damit müßte es möglich sein, eine Kanalcodierung zu definieren, die bei einer höchstmöglichen Frequenzökonomie eine geringe Qualitätsbeeinträchtigung bei gleichzeitig hohem Störpegel im Übertragungskanal liefert. Bei der Optimierung eines solchen Prozesses wird dem mobilem Empfang besondere Aufmerksamkeit gewidmet.
Andere Konzepte zur Kanalcodierung (Quelle: 18) lassen die Eigenschaften der Quelle unberücksichtigt und sehen einen virtuell fehlerfreien Kanal vor, der für die Übertragung allgemeiner Daten geeignet ist, wobei jedes ohne Ansehen der Wichtigkeit gleich codiert wird. Das bedeutet, zugefügte Redundanz für jedes Datenbit gleich groß ist. Damit wird die Möglichkeit einer minimalen Datenrate nicht ganz ausgeschöpft, da die Bandbreite des Kanals, die für eine bestimmte Übertragung notwendig ist, nicht minimiert werden kann. Dies bedeutet, daß ein transparenter Datenkanal zwar eine fehlerfreie Übertragung von irgendwelchen Daten sogar bei hohen Fehlerraten ermöglicht, daß jedoch bei einer Beschränkung auf die Übertragung von Tonsignalen dieser Weg bezüglich einer minimalen Kanalbitrate nicht optimal ist.
Die Fehlerschutzmaßnahmen können auch darin bestehen, wichtige Teile der Quellencodierung zu wiederholen oder vorab zu senden. Auch in diesem Fall könnten die Maßnahmen der Quellencodierung zugeschlagen werden. Sie lassen sich aber auch als präventive Hilfen für eine Fehlerkorrektur oder -verschleierung von langdauernden Burstfehlern verstehen, auf die die eigentlichen Kanalcodierungen nicht zugeschnitten sind.
Im folgenden wird davon ausgegangen, daß bei der Decodierung nach einer Fehlererkennung im Empfänger die Fehlerkorrektur und -verschleierung einerseits auf der Basis üblicher Faltungs- und Blockcodes (z. B. Viterbi, Reed Solomon oder Golay Code) durchgeführt werden. Diese Korrekturen spielen sich in kurzen Signalabschnitten ab. Andererseits kann jedoch auch eine Fehlerverschleierung auf der Basis anderer Maßnahmen (z. B. durch Signalwiederholungen oder Nutzung der stereofonen Irrelevanz) durchgeführt werden. Diese sollen auch längere Signalstörungen in ihren Auswirkungen überbrücken oder mildern.
Starke Störungen einer Rundfunkübertragung können dazu führen, daß nach Ausschöpfen aller Möglichkeiten der Fehlererkennung, Fehlerkorrektur und -verschleierung die gestörten Signalabschnitte nicht mehr decodierbar sind. Eine hieraus resultierende Stummschaltung des Empfängers würde jedoch als lästig empfunden werden und erfordert somit eine Maßnahme, welche eine Rekonstruktion des gestörten Tonsignals anhand störungsfrei übertragener Signalanteile ermöglicht.
Störungen werden bei zeitsimultaner Übertragung von Stereosignalen im allgemeinen beide Stereokanäle gleichzeitig treffen. Dies bedeutet, daß bei starker Störung, z. B. durch Mehrwegeempfang, für eine Zeit lang das Signal komplett gestört ist, und somit eine Rekonstruktion nicht möglich ist. Mit der Verfügbarkeit des Signalanteils von wenigstens einem der beiden Kanäle ließe sich jedoch eine Rekonstruktion des gestörten Stereosignals unter der Voraussetzung, daß beide Kanäle eine gewisse Korrelation zueinander aufweisen, auf verhältnismäßig einfache Weise realisieren. Voraussetzung hierbei ist, einen der beiden Kanäle um eine bestimmte Dauer, die etwa der maximal auftretenden Stördauer entsprechen sollte, zeitverzögert auszusenden (siehe Abb. 6).
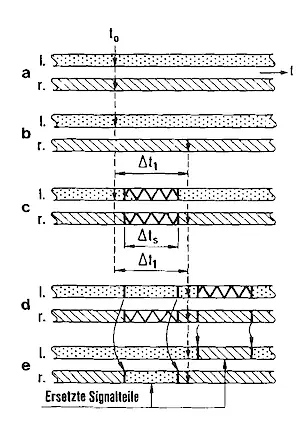
Nach einer anschließenden Resynchronisation im Empfänger kann gewährleistet werden, daß zu einem bestimmten Zeitpunkt stets nur einer der beiden Kanäle gestört wurde. Aufgrund der bei einer stereofonen Übertragung oft hohen Ähnlichkeit des Informationsgehalts der beiden Stereokanäle, besteht nun die Möglichkeit, den gestörten Signalabschnitt durch den ungestörten Signalabschnitt des anderen Kanals zu ersetzen.
Die Anwendung ist möglich aufgrund der Zeiteffekte des räumlichen Hörens, insbesondere der Trägheit des Gehörs beim Richtungs- und Entfernungshören (Quellen: 19, 20). Unter dem Begriff „Trägheit des Gehörs beim räumlichen Hören“ wird seine Eigenschaft verstanden, auf eine Veränderung des Ortes der Schallquelle nicht beliebig schnell mit einer Veränderung des Ortes des Hörereignisses zu reagieren. Diese Trägheit muß immer dann beachtet werden, wenn man es mit zeitlich schnell veränderlichen Schallereignisorten zu tun hat. Ein derartiges Phänomen ist für das beschriebene Substitutionsverfahren von großer Bedeutung. Untersuchungen zur Trägheit des Richtungshörens mit natürlichen Sprach- und Musiksignalen (Quelle: 21) zeigen, daß auch geübte Hörer nicht in der Lage sind, kurzzeitige Vertauschungen der beiden Kanäle von stereofonem Programmaterial unter 160 ms sicher zu erkennen. Die Experimente weisen jedoch eine gewisse Abhängigkeit vom verwendeten Programmaterial auf.
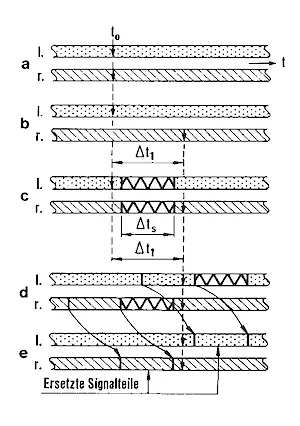
Eine Möglichkeit der Fehlerverschleierung bei lang andauernden Bitfehlerstörungen von äußerst schwach korrelierten Kanälen ist durch einen entsprechenden Ersatz aus demselben Kanal, d. h. durch Wiederholung eines Signalabschnittes gegeben. Abb. 7 zeigt die beiden Kanäle eines Stereosignals, wie sie zunächst im Sender vorliegen (a, b). Auch in diesem Fall werden die beiden Kanäle um eine Zeit, die der maximal angenommenen Stördauer entspricht, gegeneinander verzögert.
Prinzipiell arbeitet diese Substitutionsmethode auch ohne eine gegenseitige Verzögerung. Dennoch sprechen zwei Gründe für die Beibehaltung einer Verzögerung.
Diese Substitution sollte alternativ, d.h. nur bei geringer Korrelation der beiden Kanäle erfolgen.
Es bleibt dadurch gewährleistet, daß zu einem bestimmten Zeitpunkt jeweils nur in einem Kanal eine Rekonstruktion einer Störung auftritt, während das Signal des anderen Kanals ungestört weiterläuft. Auf einen Zeitsprung, der in beiden Kanälen gleichzeitig stattfindet, reagiert das Gehör empfindlicher, als auf einen Sprung in nur einem Kanal, dessen subjektive Störwirkung durch das kontinuierlich weiterlaufende Signal des ungestörten Kanals gemindert wird.
Untersuchungen mit beiden Substitutionsverfahren zeigten, daß es auch beim Versagen der Fehlerkorrektur aufgrund längerer Fehlerbursts möglich ist, durch Ausnutzung der Irrelevanz im stereofonen Signal, Störungen mit einer Dauer bis zu 160 ms zu überbrücken. Bei der Übertragung von Sprache ergibt sich der Vorteil, daß die Sprachverständlichkeit erhalten bleibt. Diese Untersuchungen wurden alle . bei kritischen Abhörbedingungen, d.h. meist mit Kopfhörer durchgeführt. Wenn man davon ausgeht, daß solche Maßnahmen in erster Linie nur bei äußerst ungünstigen Empfangsbedingungen, d.h. entweder am Rand eines Versorgungsgebietes, oder im fahrenden KFZ bei starkem Mehrwegeempfang stattfinden, kann eine derartige kritische Form des Abhörens ausgeschlossen werden. Da zusätzlich mit einem gewissen Geräuschpegel im Fahrgastinnenraum zu rechnen ist, wird durch die verdeckende Wirkung eines solchen Störpegels erreicht, daß eine Rekonstruktion des gestört übertragenen Tonsignals durch eine Substitution entweder überhaut nicht, oder nur in äußerst geringem Maße wahrgenommen wird. Gegenüber einer einfachen „Stummschaltung“ stellen diese Maßnahmen erhebliche Verbesserungen dar.
Störungen mit einer Dauer von weniger als 20 ms erweisen sich hinsichtlich ihrer Rekonstruierbarkeit generell als unkritisch. Bei längeren Störzeiten erlangt die Auswahl der auf das momentane Signal angepaßten Substitutionsmethode eine gewisse Bedeutung. Abhängig vom Signal müßte der Empfänger die Auswahl für das optimale Substitutionsverfahren treffen.
Um bei der Codierung hochwertiger Tonsignale eine minimale Datenrate zu erzielen, müssen die Mithörschwellen des Gehörs konsequent berücksichtigt werden. Beim MASCAM-Verfahren wird die aktuelle, signalabhängige Mithörschwelle berechnet und danach die Quantisierung der einzelnen Teilbandsignale bemessen. Diese dynamische Bitzuweisung führt zu Datenraten, die signalabhängig schwanken. Die auftretenden Maxima haben einen Wert von ca. 100 kbit/s bei einer Abtastfrequenz von 48 kHz. Durch die signalabhängige Schwankung der Bitrate ergeben sich besondere Möglichkeiten der Anpassung der MASCAM-Codierung an unterschiedliche Anforderungen. Bei zeitunkritischer Übertragung lassen sich die signalabhängigen Schwankungen des Bitflusses mithilfe eines Pufferspeichers mildern. Dadurch wird die maximal erforderliche Datenrate reduziert. Für Übertragungen, die nur kleine Signalverzögerungen erlauben, gleichzeitig aber eine konstante Datenrate erfordern, ergibt sich eine signalabhängig schwankende Bitflußreserve, die ebenfalls abhängig von der Anwendung nutzbar ist.
MASCAM-codierte Signale können damit Datenraten gewährleisten, die auch unter Berücksichtigung verschiedener Anforderungen und Kanaleigenschaften minimal sind. Der sendeseitige Coder muß diese Anforderungen erfüllen, sodaß hier ein relativ großer Aufwand an digitaler Hardware, bzw. Rechenleistung zur Verfügung gestellt werden muß. Demgegenüber ergibt sich der erforderliche Aufwand für den Decoder im wesentlichen durch die inverse Filterbank. Es ist damit zu rechnen, daß beim mobilen Empfang digitaler Hörrundfunkprogramme ausgeprägte Schwankungen der Empfangsbedingungen auftreten. Im Falle eines ungenügenden Fehlerschutzes ist eine digitale Übertragung von Tonsignalen sehr empfindlich gegenüber Bitfehlerstörungen. Eine hohe inhärente Fehlersicherheit der codierten Signale gegenüber Übertragungsstörungen ist hierbei eine wichtige Eigenschaft des Codierverfahrens.
Um einen ausreichenden Fehlerschutz zu gewährleisten, ist daher eine möglichst ökonomische Nutzung einer nur begrenzt zur Verfügung stehenden Kanalkapazität notwendig. Ein optimales Quellencodierverfahren sollte zunächst die irrelevanten und redundanten Anteile des Tonsignals eliminieren, um somit eine sehr niedrige Datenrate für die Codierung des Tonsignals zu erreichen. Anschließend kann nun z. B. für die Auslegung des Fehlerschutzes ein Teil der frei gewordenen Datenrate gezielt eingesetzt werden. Durch eine Berücksichtigung der Quellen- und Kanalcodierung können somit die Erfordernisse des Gehörs bezüglichst einer optimalen Unterdrückung der Wahrnehmung von Bitfehlerstörungen berücksichtigt werden.
/1/ Theile, G., Stall, G., and Link, M.: Low bit-rate coding of high quality audio signals. 82nd AES Convention, 1987, Preprint No. 2432.
/2/ Krahe, D.: Ein Verfahren zur Datenreduktion bei digitalen Audiosignalen unter Ausnutzung psychoakustischer Phänomene. Rundfunkt. Mitt. 30, 1986, pp. 117-123.
/3/ Brandenburg, K .: High quality sound coding at 2.5 bit/sample. 84th AES Convention, J 988, Preprint No.2582.
/4/ Vörös, P.: High Quality Sound Codrng within 2"64 kbit/s using Instantaneous Dynamic Bit-Allocation. Proc. ICASSP, New York, April 1988, pp. 2536-2539.
/5/ Johnston, J.: Transform Goding of Audio Signals Using Perceptual Noise Criteria. IEEE Journal on selected areas in communication, Vol.6, No.2, February 1988, pp. 314-323.
/6/ Theile, G., Stall, G., and Link M.: Low bit-rate coding of high-quality audio signals. An introduction to the MASCAM system. EBU Review - Technical No. 230, August 1988, pp. 158-181.
/7/ Stall, G. and Theile, G.: Neue digitale Tonübertragungsverfahren: Wie erfolgt die Beurteilung der Tonqualität? Bericht 14. Tonmeistertagung, 1986, pp. 472-432.·
/8/ Stall, G., Link, M., and Theile, G.: Masking-pattern adapted subband coding: use of the dynamic bit-rate margin. 84th AES Convention, 1988, Preprint No. 2585.
/9/ Jakubowski, H. and Twietmeyer, H.: The German DBS Digital Sound Broadcasting System: Audio Goding Methods. 77th AES Convention, 1985, Preprint No. 2179.
/10/ Crochiere, R.E.: Sub-band coding. The Bell Sys. Techn. J., Val. 60, No. 7, September 1981, pp. 1633-1653.
/11/ Jayant, N.S. and Noll,P.: Digital Goding of Waveforms. 1984 Prentice Hall, lnc. Englewood Cliffs, New Jersey 07632, 1984.
/12/ Spille, J. and Schröder, E.F.: Vergleich mehrerer für eine Teilbandcodierung geeigneter Filterfamilien unter besonderer Berücksichtigung der Wellendigitalfilter, in ITG-Fachbericht 106 „Hörrundfunk“, Mainz 1988.
/13/ Zwicker, E. and Feldtkeller, R.: Das Ohr als Nachrichtenempfänger. S. Hirzel Verlag, Stuttgart, 1967.
/14/ Cox, R.V„ Hagenauer, J., Seshadri. N. and Sundberg, C.E.: A Sub-Band Coder Designed for Combined Source and Channel Coding, in Proc. of the lnt. Conf. on Acoust .. Speech and Signal Proc. ICASSP 1988.
/15/ Terhardt, E., Stall, G. and Seewann M.: Algorithm for extraction of pitch and piteh salienee from complex tonal signals. J. Aeoust. Soc. Am. 71 (3), March l 982, pp. 679-688.
/16/ Fletcher, H. and Galt, R.H.: The perception of speech and its relation to telephony, J. Aeoust. Soe. Am. 22, 1950, pp. 89-151.
/17/ Weck, Ch., and Theile, G.: Digital Audio Broadeasting: Optimizing of a combined concept of source and ehannel eoding with respect of subjective criteria, in International Broadcasting Convention, Brighton, Sept. 1988, Conf. Publieation No. 293, pp. 360-363.
/18/ Alard, M. and Lassalle, R.: Principles of modulation and ehannel coding for digital broadeasting for mobile reeeivers. EBU Review-Technical, No. 224, August 1987, pp. 168-190.
/ 19/ Blauert, J.: Ein Beitrag zur Trägheit des Richtungshörens in der Horizontalebene. Acustica Val. 20, 1968, pp. 200-206.
/20/ Franssen, N.V.: Die Phänomenologie des Richtungshörens. Stereophonie. Eindhoven: Philips Technische Bibliothek, l 963.
/21/ Plenge, G.: On the Behaviour of Listeners to Stereophonie Sound Reproduction and the Consequences for the Theories of Sound Perception in a Stereophonie Sound Field. 83rd AES Convention, l 987. Preprint No. 2532.

Günther Theile war von 1977 bis 2008 am Institut für Rundfunktechnik tätig. Auf ihn gehen zahlreiche wichtige Entwicklungen im Bereich der Audiotechnik zurück.

Gerhard Stoll (†) war maßgeblich an der Entstehung des digitalen Rundfunks und vielen weiteren Entwicklungen beteiligt.